
Zonal travel cost studies often rely on very small datasets. Conventional estimates of precision are unreliable in those circumstances.
Originally posted 19/6/2015. Re-posted following site reorganisation 21/6/2016.
The zonal travel cost method (ZTCM) for estimating the use value of recreational sites should never be expected to yield highly accurate results. One limitation is that it is subject to aggregation bias arising from averaging of data within zones (1a-b). Another is that, as shown in a previous post, results can be sensitive to zone definition. Nevertheless, it continues to be used because alternative methods have their own limitations.
This post considers the precision of one of the results of a ZTCM study relating to Lake Mokoan in Victoria, Australia, reported in Herath (1999) (2). It is not a full review of Herath’s paper, in which ZTCM is only one of several valuations methods used.
The number of visitors interviewed in Herath’s on-site survey was 90. That may seem a reasonably sized sample from which to draw inferences. In ZTCM, however, we use regression analysis to fit a trip-generating function not to individual data but to zonal aggregates. The study’s effective sample size was not 90, but the number of zones over which the individual data was aggregated, which was 5. Such a small sample should set warning bells ringing, since any conclusions drawn will be liable to considerable sampling error.
The duration of the survey is not reported, but it is stated that visit numbers averaged 10 per day on weekdays and 40 per day at weekends (3): given 90 interviews this suggests that the survey covered only a few days (not necessarily a single continuous period).
The normal aims of a ZTCM study are to estimate the demand curve for visits to a site and then to take the implied consumer surplus as an estimate of the site’s use value. Here I will focus on the essential preliminary stage of estimating the trip-generating function relating annual visit rate to travel cost. Herath compared several functional forms and found that a double log form gave the best fit (
Herath follows the common practice of scaling up the survey data to reflect total annual visits, and then calculating the regression with annual visit rate per 1,000 population as the dependent variable. Personally, I prefer to scale up only after calculating a regression with an unscaled dependent variable (surveyed visits per capita). Either approach should yield the same results, but the latter is conceptually simpler when considering (as we will below) the variance of the dependent variable.

The analysis that follows will consider the precision of these coefficient estimates as measured by their standard errors. To focus on the key points at issue, I shall assume that all data were accurately measured and the trip-generating function was correctly specified as stated in Table 1, and ignore possible challenges to those assumptions.
In outline, there are two problems with the way in which these standard errors have been obtained. Firstly, standard errors estimated in the conventional way from the sum of squared residuals are subject to considerable sampling error when the sample size and therefore the number of residuals used in the calculation is small. The data points may just happen to be closer to or further from the fitted line than is representative of the population of possible zones around the site. Secondly, standard errors estimated by OLS are unreliable in the presence of heteroscedasticity, to which ZTCM is prone. The variance of a zonal visit rate will depend on the zonal population (larger population implies smaller variance) and on the visit rate itself (higher visit rate implies larger variance) (5).
What’s more, these two problems are difficult to separate since the small sample size also undermines some of the methods most commonly used in addressing heteroscedasticity. Inferences about the presence or form of heteroscedasticity from inspection or analysis of residuals are unreliable when the number of residuals is small. Use of robust (heteroscedasticity-consistent) standard errors is unreliable with small samples (6). Two-stage estimation, in which OLS estimates are used in obtaining weights designed to correct for heteroscedasticity in a second stage weighted least squares (WLS) estimation, is also unreliable because weights obtained in this way will be subject to considerable sampling error.
Let’s look more closely at how sampling error can affect the standard errors. The true variances (squares of standard errors) of estimates of regression coefficients are given by (7):
![Var[\hat{B}]= \sigma_0^2.(X'X)^{-1}\qquad(E1)](https://s0.wp.com/latex.php?latex=Var%5B%5Chat%7BB%7D%5D%3D+%5Csigma_0%5E2.%28X%27X%29%5E%7B-1%7D%5Cqquad%28E1%29&bg=ffffff&fg=000000&s=1&c=20201002)
Here B is the vector of coefficients and X the matrix of values of the independent variables. 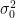

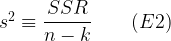
The problem with this is that the variance estimator, as its name suggests, is merely an estimator. It is an unbiased estimator of
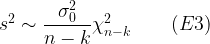
In the present case n = 5 and k = 2, so this reduces to:

Although
So what can we do? It’s all very well to make the general observation that conventional standard errors calculated from very small samples and in the presence of heteroscedasticity are extremely unreliable. But can we determine whether the standard errors calculated from a particular dataset are too large or too small? There are two features of the present case that can help. One is the logged dependent variable which, as it happens, deals neatly with heteroscedasticity due to differing zonal populations. For a given zone, let V be the number of visits identified by the survey from that zone, N the zonal population, and VR the unscaled visit rate. Since N is a constant for any one zone so that Ln N is also a constant and Var[Ln N] is zero, we have:
![Var[Ln VR] = Var[Ln(V/N)] = Var[Ln V - Ln N] = Var[Ln V]+Var[Ln N]](https://s0.wp.com/latex.php?latex=Var%5BLn+VR%5D+%3D+Var%5BLn%28V%2FN%29%5D+%3D+Var%5BLn+V+-+Ln+N%5D+%3D+Var%5BLn+V%5D%2BVar%5BLn+N%5D&bg=ffffff&fg=000000&s=1&c=20201002)
and so:
![Var[Ln VR] = Var[Ln V]\qquad(E5)](https://s0.wp.com/latex.php?latex=Var%5BLn+VR%5D+%3D+Var%5BLn+V%5D%5Cqquad%28E5%29&bg=ffffff&fg=000000&s=1&c=20201002)
Thus we have shown that Var[Ln VR] does not depend on N.
The other helpful feature is that the aggregate nature of the dependent variable enables us, on reasonable assumptions, to draw a conclusion about its variance. We start from the observation that the value of V, the number of visits from a particular zone identified by a survey, is a consequence of many separate decisions by the many individuals in that zone. Since it is unlikely that any individual will visit more than once within the scope of the survey, we can treat the number of visits v by an individual within the scope of the survey as a Bernoulli variable (equalling either 0 or 1). Writing p for the probability that v = 1, and using standard properties of the Bernoulli distribution, we have:
![E[v] = p\qquad(E6)](https://s0.wp.com/latex.php?latex=E%5Bv%5D+%3D+p%5Cqquad%28E6%29&bg=ffffff&fg=000000&s=1&c=20201002)
![Var[v] = p-p^2\qquad(E7)](https://s0.wp.com/latex.php?latex=Var%5Bv%5D+%3D+p-p%5E2%5Cqquad%28E7%29&bg=ffffff&fg=000000&s=1&c=20201002)
We must expect that p varies between individuals within the zone: some will like visiting lakes more, or have more leisure time, than others. However, it is reasonable to assume that the p are all small, since people like variety in their leisure activity, so that even if someone likes visiting lakes and likes visiting that lake in particular, the probability that they will visit it within a particular period of a few days will be small. Hence the squared term in E7 can be ignored. It is also reasonable to assume that the p are largely independent, because decisions by one individual are unlikely to influence more than a tiny proportion (family members and a few friends, perhaps) of the thousands within the same zone). It can reasonably be assumed therefore that the distribution of V, the sum of the v for all the individuals in the zone, approximates to a Poisson distribution (9) with the properties:
![E[V] = Var[V] = \sum p\qquad(E8)](https://s0.wp.com/latex.php?latex=E%5BV%5D+%3D+Var%5BV%5D+%3D+%5Csum+p%5Cqquad%28E8%29&bg=ffffff&fg=000000&s=1&c=20201002)
where the sum is over all the individuals in the zone.
To use E8 to draw a conclusion about Var[Ln VR] we need to express the latter as a function of Var[V]. If Z is a Poisson variable with mean and variance 
![Var[Ln Z] \approx \dfrac{12\lambda^2 + 18\lambda + 11}{12\lambda^3}\qquad(E9)](https://s0.wp.com/latex.php?latex=Var%5BLn+Z%5D+%5Capprox+%5Cdfrac%7B12%5Clambda%5E2+%2B+18%5Clambda+%2B+11%7D%7B12%5Clambda%5E3%7D%5Cqquad%28E9%29&bg=ffffff&fg=000000&s=1&c=20201002)
Its error is between 3% and 6% for 
![Var[Ln VR] \approx \dfrac{12(E[V])^2+18E[V]+11}{12(E[V])^3}\qquad(E10)](https://s0.wp.com/latex.php?latex=Var%5BLn+VR%5D+%5Capprox+%5Cdfrac%7B12%28E%5BV%5D%29%5E2%2B18E%5BV%5D%2B11%7D%7B12%28E%5BV%5D%29%5E3%7D%5Cqquad%28E10%29&bg=ffffff&fg=000000&s=1&c=20201002)
For convenience I will abbreviate the right-hand expression in E10 as g(E[V]). From E10 we can infer that heteroscedasticity due to differences in visit rates is still present after the log transformation. This can in principle be addressed by WLS estimation, the necessary weighting factor being the reciprocal of g(E[V]). This is equivalent to OLS estimation of the model (with u as the error term):
![(g(E[V]))^{-0.5}Ln VR)=(g(E[V])) ^{-0.5}B1+(g(E[V])) ^{-0.5}B2(Ln TC)+u\qquad(E11)](https://s0.wp.com/latex.php?latex=%28g%28E%5BV%5D%29%29%5E%7B-0.5%7DLn+VR%29%3D%28g%28E%5BV%5D%29%29+%5E%7B-0.5%7DB1%2B%28g%28E%5BV%5D%29%29+%5E%7B-0.5%7DB2%28Ln+TC%29%2Bu%5Cqquad%28E11%29&bg=ffffff&fg=000000&s=1&c=20201002)
To confirm that this is homoscedastic, we first show that the dependent variable is homoscedastic. Noting that g(E[V]) is constant for any particular zone and using E10 we have:
![Var[(g(E[V]))^{-0.5}Ln VR] = g(E[V])^{-1}Var[Ln VR] \approx g(E[V])^{-1}g(E[V])](https://s0.wp.com/latex.php?latex=Var%5B%28g%28E%5BV%5D%29%29%5E%7B-0.5%7DLn+VR%5D+%3D+g%28E%5BV%5D%29%5E%7B-1%7DVar%5BLn+VR%5D+%5Capprox+g%28E%5BV%5D%29%5E%7B-1%7Dg%28E%5BV%5D%29&bg=ffffff&fg=000000&s=1&c=20201002)
and so
![Var[(g(E[V]))^{-0.5}Ln VR] \approx 1\qquad(E12)](https://s0.wp.com/latex.php?latex=Var%5B%28g%28E%5BV%5D%29%29%5E%7B-0.5%7DLn+VR%5D+%5Capprox+1%5Cqquad%28E12%29&bg=ffffff&fg=000000&s=1&c=20201002)
Given our assumption that the regression model is correctly specified, we can infer that it is homoscedastic since for any zone the regression variance
![\sigma_0^2 = Var[u] = Var[(g(E[V]))^{-0.5}Ln VR] \approx 1 \qquad(E13)](https://s0.wp.com/latex.php?latex=%5Csigma_0%5E2+%3D+Var%5Bu%5D+%3D+Var%5B%28g%28E%5BV%5D%29%29%5E%7B-0.5%7DLn+VR%5D+%5Capprox+1+%5Cqquad%28E13%29&bg=ffffff&fg=000000&s=1&c=20201002)
However, the problem remains that we do not have reliable estimates of E[V] for each zone to slot into E11. We cannot therefore undertake a single definitive WLS estimation leading to coefficient estimates with reasonably reliable standard errors.
To make further progress, we can consider two cases. The pair of true values of the regression coefficients are either within or outside the 95% confidence ellipse defined by the OLS results. This ellipse (see Figure 1 below) is defined by the results in Table 1 together with the estimated covariance between the constant and travel cost coefficients. Its meaning is that, on repeated sampling and if the standard errors (and covariances) are correct, 95% of such ellipses will contain the true pair of coefficients. Note that Figure 1 is based on the unscaled visit rate (hence the range of the constant coefficient is much lower than its estimate in Table 1).
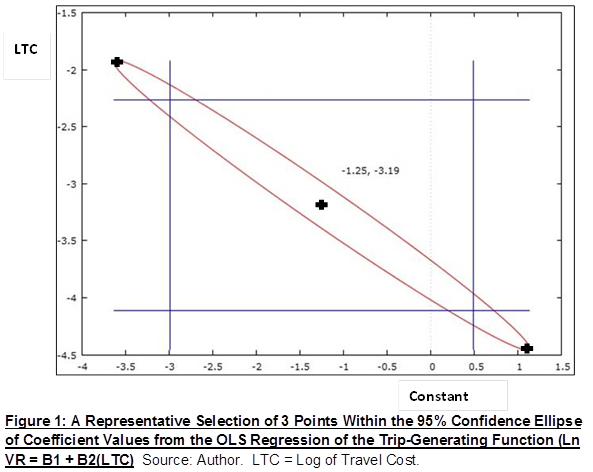
If the true coefficient values are outside this ellipse, it could be that the standard errors are correct and the sample data happens to be such that the ellipse is one of the unlucky 5%. This is an unlikely but not impossible scenario. Since we know that the standard errors are very unreliable, however, a more plausible interpretation is that the standard errors are too small, and that a confidence ellipse based on the true standard errors would have included the true coefficient values.
The case of true coefficient values within the ellipse requires a different type of reasoning. We select a representative sample of pairs of coefficient values from different regions of the ellipse. Since the ellipse is long and narrow, from top left to bottom right, I shall illustrate the method using three pairs of coefficient values identified as ‘top left’, ‘centre’ and’ bottom right’. For each such pair, we use the regression model to calculate the implied values of E[V] for each zone, and substitute these into E12 to obtain weights for WLS estimation of the model.
Having obtained the estimated coefficients and standard errors for each pair, there is a further important step to be taken. Given our conclusion (E13) that
![Var[\hat{B}] = \sigma_0^2.(X'X)^{-1} = \dfrac{\sigma_0^2}{s^2}.(s^2.(X'X)^{-1}) \approx\dfrac{1}{s^2}.(Var[\hat {B}]_{Conv})\qquad(E14)](https://s0.wp.com/latex.php?latex=Var%5B%5Chat%7BB%7D%5D+%3D+%5Csigma_0%5E2.%28X%27X%29%5E%7B-1%7D+%3D+%5Cdfrac%7B%5Csigma_0%5E2%7D%7Bs%5E2%7D.%28s%5E2.%28X%27X%29%5E%7B-1%7D%29+%5Capprox%5Cdfrac%7B1%7D%7Bs%5E2%7D.%28Var%5B%5Chat+%7BB%7D%5D_%7BConv%7D%29%5Cqquad%28E14%29&bg=ffffff&fg=000000&s=1&c=20201002)
Here the subscript ‘Conv’ identifies conventional estimates calculated using
![se[\widehat{B_j}] \approx \dfrac{se[\widehat {B_j}]_{Conv}}{s}\qquad(E15)](https://s0.wp.com/latex.php?latex=se%5B%5Cwidehat%7BB_j%7D%5D+%5Capprox+%5Cdfrac%7Bse%5B%5Cwidehat+%7BB_j%7D%5D_%7BConv%7D%7D%7Bs%7D%5Cqquad%28E15%29&bg=ffffff&fg=000000&s=1&c=20201002)
Table 2 below shows the results of the WLS estimations. All three estimations use the same underlying data; they differ only in the coefficient values used in obtaining the weights.

Table 2 shows that the standard errors obtained by WLS estimation and adjusted as described above are considerably higher than those in Table 1. The standard errors based on the top left point are 35% and 41% higher respectively for the constant and travel cost coefficients; for the other two points, the percentages are much higher. While it has not been proved that standard errors based on other points within the ellipse will also be considerably higher than those in Table 1, it appears a reasonable inference.
Whether the true values of the coefficients lie outside or inside the ellipse, therefore, we can conclude, to at least a reasonable degree of likelihood, that the standard errors in Table 1 are underestimated.
If we can dispense with 
Supporting Analysis
I can provide the supporting analysis on request (in MS Office 2010 format). My email address is in About.
Notes and References
1a. Rosenthal D H & Anderson J C (1984) Travel Cost Models, Heteroskedasticity, and Sampling Western Journal of Agricultural Economics 9(1) p 58-60; http://ageconsearch.umn.edu/bitstream/32368/1/09010058.pdf
1b. Hellerstein D (1995) Welfare Estimation Using Aggregate and Individual-Observation Models: A Comparison Using Monte Carlo Techniques American Journal of Agricultural Economics 77 (August 1995) p 623
2. Herath G (1999) Estimation of Community Values of Lakes: A Study of Lake Mokoan in Victoria, Australia Economic Analysis & Policy Vol 29 No 1 pp 31-44
3. Herath, as 2 above, p 35.
4. Herath, as 2 above, p 37.
5. Christensen J & Price C (1982) A Note on the Use of Travel Cost Models with Unequal Zonal Populations: Comment Land Economics 58(3) pp 396 & 399
6. Imbens G W & Kolesar M (Draft 2015) Robust Standard Errors in Small Samples: Some Practical Advice pp 1-2 https://www.princeton.edu/~mkolesar/papers/small-robust.pdf
7. Ruud P A (2000) An Introduction to Classical Econometric Theory Oxford University Press p 157. Note that the argument of E1 to E4 assumes both homoscedasticity and normality of error terms (but it would be optimistic to expect that conventional standard errors would be more reliable when these assumptions do not hold).
8. Ruud, as 7 above, p 199
9. The distribution of V approximates to a Poisson binomial distribution, and this in turn approximates to a Poisson distribution. See Hodges J L Jr & Le Cam L (1960) The Poisson Approximation to the Poisson Binomial Distribution The Annals of Mathematical Statistics 31(3) pp 737-740 http://projecteuclid.org/euclid.aoms/1177705799

