Within a static model of a fishery one can identify levels of fishing effort for maximum yield, maximum profits and maximum welfare. Where demand is downward-sloping, effort for maximum welfare will normally be above that for maximum profits but below that for maximum yield.
Originally posted 14/6/2014. Re-posted following site reorganisation 21/6/2016.
In a previous post discussing the reform of the EU’s Common Fisheries Policy, I outlined a model of a fishery in steady state with price flexibility. Here I present that model in mathematical form.
Bioeconomic models of fisheries often take the price of fish as given. This could be for the good reason that a model is intended to represent a local fishery whose output is too small to affect the market price of fish. In the context of textbooks on natural resource economics, there may also be a pedagogical motive. The combination of a biological growth function, a harvest function and a cost function is sufficient to demonstrate some important results – such as the distinction between open access and private property equilibria -, and may be judged complex enough for an introductory treatment, without the additional complication of downward-sloping demand for fish.
A consequence of a fixed price assumption is that there can be no consumer surplus. Hence the private property equilibrium, maximising profits (producer surplus), is also the social optimum, maximising economic welfare defined as the sum of the consumer and producer surpluses (1). Once the fixed price assumption is relaxed, however, it no longer follows that the same fishing effort will maximise both profits and welfare. Although this has been recognised in the literature at least since it was shown by Anderson (1973) (2), the point bears reiteration since it is commonly omitted in introductory textbooks.
As in other economic sectors, demand at industry level should be expected to be downward-sloping, raising the possibility that restriction of output to maximise profit could reduce overall welfare. Whether this will actually occur will depend on the structure and regulation of the industry. A monopoly is perhaps unlikely in a fishing context. A more plausible scenario is that regulation initially intended to address a situation of open access and over-fishing might evolve into a policy of maximising industry profits at the expense of the consumer.
The complexity of many bioeconomic models of fisheries has as much to do with the proliferation of letters standing for variables or parameters as to any complexity in the mathematics itself. Judicious choice of units can limit the number of letters needed. Let us measure fish stock, X, in units such that the carrying capacity (sometimes represented by k) is one. The biological rate of growth of fish stock in the absence of harvesting, F, must be measured in units of fish stock per unit of time. For fish stock we must use the units just defined, but let us measure time in units such that we can write the standard logistic growth function without a growth parameter (sometimes represented by r) as simply:
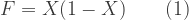
Fish harvest, H, is sometimes treated as the product of fish stock, fishing effort, E, and a coefficient representing fishing technology, but let us measure fishing effort in units such that the technology coefficient is one. The harvest function then is simply:

No doubt these units would be inconvenient for practical use, but in exploring the properties of a model all that matters is consistency (3). Thus, for example, every variable we use that represents a rate per unit of time – harvest H, cost of fishing effort C, revenue from fish sales R – must use the time unit defined above.
The condition for a steady state is that the rate of harvest should exactly offset the rate of biological growth:
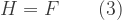
From (1), (2) and (3) we may infer the following relation between fish stock and effort in steady state:

Hence, unless X = 0:


This relation provides some insight into the units we have defined for effort: since X must lie in the range from 0 to 1 (1 being the carrying capacity), E must also lie in the range from 0 to 1.
We make the common assumption that fishing costs, C, are a linear function of fishing effort:

For demand, we also assume linearity, but it is convenient to focus on the inverse demand function representing the unit price of fish P in terms of harvest:

It is assumed here that all fish harvested is sold at once, so that quantity demanded can be equated with harvest.
Using (2), (4) and (6) we may infer the steady-state revenue-effort relation:




This is the relation which in my previous post was referred to as a “flexible-price steady state revenue-effort curve” and shown in blue on Diagram 2.
We can now consider the respective levels of fishing effort needed to maximise harvest, profits (producer surplus) and welfare, in each case sustainably. The method is in principle the same in each case: we first express the quantity to be maximised as a function of effort, then use elementary calculus to find the maximum. However, the cases of profit and welfare lead to cubic equations that are difficult to solve. Instead, we will show that:
- the level of effort for maximum profit is less than that for maximum harvest;
- welfare increases with effort at the point of maximum profit;
- welfare decreases with effort at the point of maximum harvest.
From the above it follows that effort for maximum welfare will be above that for maximum profits but below that for maximum harvest.
From (2) and (4) the steady state harvest-effort relation is:

Setting the derivative equal to zero to find the maximum:
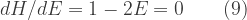
Hence for maximum harvest (maximum sustainable yield) E = 0.5. Note that relation (8) is symmetrical about the axis defined by E = 0.5. Thus any harvest obtainable at E* > 0.5 can also be obtained with less effort at (1 – E*) < 0.5. We expect therefore that both maximum profits and maximum welfare will require 0 < E < 0.5.
The steady-state relation between producer surplus, PS, and effort, from (5) and (7), is:


For a maximum we require:
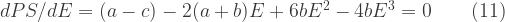
Without attempting to solve (11) for E, we now consider the case of welfare.
To express welfare, W, as a function of effort, we must first express consumer surplus, CS, as a function of harvest. In terms of a price-quantity diagram, it is the triangular area below the demand curve and above the price corresponding to the harvest. Using (6), this is:
![CS = (1/2)H(a-P) = (1/2)H[a - (a - bH)] = (b/2)H^2\qquad(12)](https://s0.wp.com/latex.php?latex=CS+%3D+%281%2F2%29H%28a-P%29+%3D+%281%2F2%29H%5Ba+-+%28a+-+bH%29%5D+%3D+%28b%2F2%29H%5E2%5Cqquad%2812%29&bg=ffffff&fg=333333&s=1&c=20201002)
From (8) and (12), the steady-state relation between consumer surplus and effort is:

Hence, from (10) and (13), the steady-state relation between welfare and effort is:
![W = PS + CS = [(a-c)E - (a+b)E^2 + 2bE^3 - bE^4] + [(b/2)E^2 - bE^3 + (b/2)E^4]\qquad(14)](https://s0.wp.com/latex.php?latex=W+%3D+PS+%2B+CS+%3D+%5B%28a-c%29E+-+%28a%2Bb%29E%5E2+%2B+2bE%5E3+-+bE%5E4%5D+%2B+%5B%28b%2F2%29E%5E2+-+bE%5E3+%2B+%28b%2F2%29E%5E4%5D%5Cqquad%2814%29&bg=ffffff&fg=333333&s=1&c=20201002)
Although (14) could be simplified by collecting like powers of E, it is convenient for our purposes to keep separate its elements deriving from the producer and consumer surplus. Hence:
![dW/dE = [(a-c) - 2(a+b)E + 6bE^2 - 4bE^3] + [bE - 3bE^2 + 2bE^3]\qquad(15)](https://s0.wp.com/latex.php?latex=dW%2FdE+%3D+%5B%28a-c%29+-+2%28a%2Bb%29E+%2B+6bE%5E2+-+4bE%5E3%5D+%2B+%5BbE+-+3bE%5E2+%2B+2bE%5E3%5D%5Cqquad%2815%29&bg=ffffff&fg=333333&s=1&c=20201002)
Substituting (9) into (15) we can infer the value of (15) at harvest-maximising effort:
![dW/dE = [(a-c) - 2(a+b)(0.5) + 6b(0.5)^2 - 4b(0.5)^3] + [b(0.5)^2 - 3b(0.5)^3 + 2b(0.5)^4]](https://s0.wp.com/latex.php?latex=dW%2FdE+%3D+%5B%28a-c%29+-+2%28a%2Bb%29%280.5%29+%2B+6b%280.5%29%5E2+-+4b%280.5%29%5E3%5D+%2B+%5Bb%280.5%29%5E2+-+3b%280.5%29%5E3+%2B+2b%280.5%29%5E4%5D&bg=ffffff&fg=333333&s=1&c=20201002)
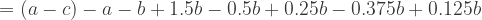

Since c, the cost coefficient, will be positive, this shows that welfare decreases with effort at harvest-maximising effort.
To infer the value of (15) at profit-maximising effort, we cannot substitute a specific value of E, but can use (11) to substitute zero for the first expression in square brackets within (15). Thus:
![dW/dE = [(a-c) - 2(a+b)E + 6bE^2 - 4bE^3] + [bE - 3bE^2 + 2bE^3]](https://s0.wp.com/latex.php?latex=dW%2FdE+%3D+%5B%28a-c%29+-+2%28a%2Bb%29E+%2B+6bE%5E2+-+4bE%5E3%5D+%2B+%5BbE+-+3bE%5E2+%2B+2bE%5E3%5D&bg=ffffff&fg=333333&s=1&c=20201002)
![= [0] + [bE - 3bE^2 + 2bE^3]](https://s0.wp.com/latex.php?latex=%3D+%5B0%5D+%2B+%5BbE+-+3bE%5E2+%2B+2bE%5E3%5D&bg=ffffff&fg=333333&s=1&c=20201002)

Since, at profit-maximising effort, 0 < E < 0.5, (17) will be positive, implying that welfare increases with effort at profit-maximising effort, provided that demand is downward sloping (b > 0). This completes the demonstration that, on the assumptions made and given sustainability, effort for maximum welfare lies above that for maximum profit but below that for maximum harvest. In the special case b = 0 (implying a given price of fish), (16) will equal zero, so that as noted above the point of maximum welfare will coincide with that of maximum profit.
Finally, some limitations should be noted. The above is a static analysis. It does not consider the path to an optimum from an initial position. Its steady-state assumption does not fully allow for the effect of current harvest, via future fish stocks, on future profits or welfare. The assumption of downward-sloping demand suggests that we are considering a fishing industry as a whole, with a harvest probably consisting of many species, so there is an implicit assumption that the simple growth and harvest functions can work reasonably well with X and H representing multi-species aggregates.
Notes and references
1. See for example Hartwick J M & Olewiler N D (2nd edn 1998) The Economics of Natural Resource Use Addison Wesley pp 110-113, where profit-maximisation is presented as socially optimal, the price of fish being taken (p 107) as given.
2. Anderson L G (1973) Optimum Economic Yield of a Fishery Given a Variable Price of Output Journal of the Fisheries Research Board of Canada 30(4) pp 509-518 http://www.nrcresearchpress.com/doi/abs/10.1139/f73-089#.U5xHWvk2zwU
3. Anyone suspecting that there is some trick in my treatment of units is invited to look at the following post I made to a mathematical question and answer website, deriving the profit-maximisation equation (equivalent of (11) above) with the conventional parameters and no special treatment of units: http://math.stackexchange.com/questions/825699/what-is-an-example-of-real-application-of-cubic-equations/830224#830224
![Var[X_L]](https://s0.wp.com/latex.php?latex=Var%5BX_L%5D&bg=ffffff&fg=333333&s=0&c=20201002) of the independent variable in the lower-level dataset.
of the independent variable in the lower-level dataset.![\boldsymbol{= \dfrac{2rt}{4Var[X_L]-t^2}}](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7B%3D+%5Cdfrac%7B2rt%7D%7B4Var%5BX_L%5D-t%5E2%7D%7D&bg=ffffff&fg=333333&s=1&c=20201002)
 ). Table 1 shows the ordinary least squares (OLS) regression results with conventional standard errors. Although the standard errors are not quoted by Herath, they are readily obtained from his coefficient estimates and t-values, or as regression output from his data.
). Table 1 shows the ordinary least squares (OLS) regression results with conventional standard errors. Although the standard errors are not quoted by Herath, they are readily obtained from his coefficient estimates and t-values, or as regression output from his data.
![Var[\hat{B}]= \sigma_0^2.(X'X)^{-1}\qquad(E1)](https://s0.wp.com/latex.php?latex=Var%5B%5Chat%7BB%7D%5D%3D+%5Csigma_0%5E2.%28X%27X%29%5E%7B-1%7D%5Cqquad%28E1%29&bg=ffffff&fg=000000&s=1&c=20201002)
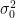 is the regression variance (the conditional variance of the error term). Since this is usually unknown it is standard practice to substitute for it the variance estimator
is the regression variance (the conditional variance of the error term). Since this is usually unknown it is standard practice to substitute for it the variance estimator  , defined as below where SSR is the sum of squared residuals, n the number of observations, and k the number of coefficients estimated.
, defined as below where SSR is the sum of squared residuals, n the number of observations, and k the number of coefficients estimated.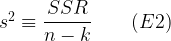
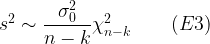

![Var[Ln VR] = Var[Ln(V/N)] = Var[Ln V - Ln N] = Var[Ln V]+Var[Ln N]](https://s0.wp.com/latex.php?latex=Var%5BLn+VR%5D+%3D+Var%5BLn%28V%2FN%29%5D+%3D+Var%5BLn+V+-+Ln+N%5D+%3D+Var%5BLn+V%5D%2BVar%5BLn+N%5D&bg=ffffff&fg=000000&s=1&c=20201002)
![Var[Ln VR] = Var[Ln V]\qquad(E5)](https://s0.wp.com/latex.php?latex=Var%5BLn+VR%5D+%3D+Var%5BLn+V%5D%5Cqquad%28E5%29&bg=ffffff&fg=000000&s=1&c=20201002)
![E[v] = p\qquad(E6)](https://s0.wp.com/latex.php?latex=E%5Bv%5D+%3D+p%5Cqquad%28E6%29&bg=ffffff&fg=000000&s=1&c=20201002)
![Var[v] = p-p^2\qquad(E7)](https://s0.wp.com/latex.php?latex=Var%5Bv%5D+%3D+p-p%5E2%5Cqquad%28E7%29&bg=ffffff&fg=000000&s=1&c=20201002)
![E[V] = Var[V] = \sum p\qquad(E8)](https://s0.wp.com/latex.php?latex=E%5BV%5D+%3D+Var%5BV%5D+%3D+%5Csum+p%5Cqquad%28E8%29&bg=ffffff&fg=000000&s=1&c=20201002)
 , a good approximation (obtained using a Taylor series expansion of the log function) is:
, a good approximation (obtained using a Taylor series expansion of the log function) is:![Var[Ln Z] \approx \dfrac{12\lambda^2 + 18\lambda + 11}{12\lambda^3}\qquad(E9)](https://s0.wp.com/latex.php?latex=Var%5BLn+Z%5D+%5Capprox+%5Cdfrac%7B12%5Clambda%5E2+%2B+18%5Clambda+%2B+11%7D%7B12%5Clambda%5E3%7D%5Cqquad%28E9%29&bg=ffffff&fg=000000&s=1&c=20201002)
 between 5 and 10, falling to less than 1% for
between 5 and 10, falling to less than 1% for ![Var[Ln VR] \approx \dfrac{12(E[V])^2+18E[V]+11}{12(E[V])^3}\qquad(E10)](https://s0.wp.com/latex.php?latex=Var%5BLn+VR%5D+%5Capprox+%5Cdfrac%7B12%28E%5BV%5D%29%5E2%2B18E%5BV%5D%2B11%7D%7B12%28E%5BV%5D%29%5E3%7D%5Cqquad%28E10%29&bg=ffffff&fg=000000&s=1&c=20201002)
![(g(E[V]))^{-0.5}Ln VR)=(g(E[V])) ^{-0.5}B1+(g(E[V])) ^{-0.5}B2(Ln TC)+u\qquad(E11)](https://s0.wp.com/latex.php?latex=%28g%28E%5BV%5D%29%29%5E%7B-0.5%7DLn+VR%29%3D%28g%28E%5BV%5D%29%29+%5E%7B-0.5%7DB1%2B%28g%28E%5BV%5D%29%29+%5E%7B-0.5%7DB2%28Ln+TC%29%2Bu%5Cqquad%28E11%29&bg=ffffff&fg=000000&s=1&c=20201002)
![Var[(g(E[V]))^{-0.5}Ln VR] = g(E[V])^{-1}Var[Ln VR] \approx g(E[V])^{-1}g(E[V])](https://s0.wp.com/latex.php?latex=Var%5B%28g%28E%5BV%5D%29%29%5E%7B-0.5%7DLn+VR%5D+%3D+g%28E%5BV%5D%29%5E%7B-1%7DVar%5BLn+VR%5D+%5Capprox+g%28E%5BV%5D%29%5E%7B-1%7Dg%28E%5BV%5D%29&bg=ffffff&fg=000000&s=1&c=20201002)
![Var[(g(E[V]))^{-0.5}Ln VR] \approx 1\qquad(E12)](https://s0.wp.com/latex.php?latex=Var%5B%28g%28E%5BV%5D%29%29%5E%7B-0.5%7DLn+VR%5D+%5Capprox+1%5Cqquad%28E12%29&bg=ffffff&fg=000000&s=1&c=20201002)
![\sigma_0^2 = Var[u] = Var[(g(E[V]))^{-0.5}Ln VR] \approx 1 \qquad(E13)](https://s0.wp.com/latex.php?latex=%5Csigma_0%5E2+%3D+Var%5Bu%5D+%3D+Var%5B%28g%28E%5BV%5D%29%29%5E%7B-0.5%7DLn+VR%5D+%5Capprox+1+%5Cqquad%28E13%29&bg=ffffff&fg=000000&s=1&c=20201002)
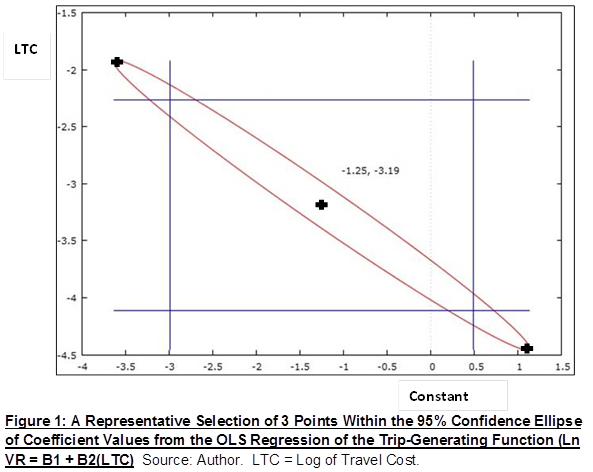
![Var[\hat{B}] = \sigma_0^2.(X'X)^{-1} = \dfrac{\sigma_0^2}{s^2}.(s^2.(X'X)^{-1}) \approx\dfrac{1}{s^2}.(Var[\hat {B}]_{Conv})\qquad(E14)](https://s0.wp.com/latex.php?latex=Var%5B%5Chat%7BB%7D%5D+%3D+%5Csigma_0%5E2.%28X%27X%29%5E%7B-1%7D+%3D+%5Cdfrac%7B%5Csigma_0%5E2%7D%7Bs%5E2%7D.%28s%5E2.%28X%27X%29%5E%7B-1%7D%29+%5Capprox%5Cdfrac%7B1%7D%7Bs%5E2%7D.%28Var%5B%5Chat+%7BB%7D%5D_%7BConv%7D%29%5Cqquad%28E14%29&bg=ffffff&fg=000000&s=1&c=20201002)
![se[\widehat{B_j}] \approx \dfrac{se[\widehat {B_j}]_{Conv}}{s}\qquad(E15)](https://s0.wp.com/latex.php?latex=se%5B%5Cwidehat%7BB_j%7D%5D+%5Capprox+%5Cdfrac%7Bse%5B%5Cwidehat+%7BB_j%7D%5D_%7BConv%7D%7D%7Bs%7D%5Cqquad%28E15%29&bg=ffffff&fg=000000&s=1&c=20201002)

 terms will not be exactly zero. A judgment has to be made, and mine is that, in the circumstances of this case, the reasoning that
terms will not be exactly zero. A judgment has to be made, and mine is that, in the circumstances of this case, the reasoning that